
데이터 엔지니어링(Data Engineering)관련 용어정리
1. 데이터 크롤링(clawling)
- 데이터 크롤링은 데이터를 수집하는 행위이고, 수집하는 프로그램을 크롤러(clawer)라고한다. 데이터를 웹에서 수집할 때, 이를 웹 크롤링이라고 하며 이에 활용되는 프로그램를 웹 크롤러라고 한다.
- WWW는 하위링크와 다양한 정보들로 이루어져있는데, 웹 크롤러가 url주소를 기반으로 해당 데이터를 자동으로 수집한다. 수집 데이터들은 html형식을 가지는데, 이 형식으로는 분석하기 어려움으로, 필요한 정보를 추출하는 parsing이라는 전환과정을 거쳐야한다. 수집된 데이터에서 필요한 정보를 추출하는 전과정 전체를 통상적으로 scrapping이라고 표현하기도한다.
2. ETL(Extract, Transformation and Loading)
-
ETL은 각각 Extract, Transformation, Loading의 약자이다.
- 내외부의 데이터를 추출하고 이를 필요에 맞게 변환한 후 저장하는 일련의 데이터 전처리 절차를 의미한다.
- ELT는 기존 ETL에서 transformation과 loading의 순서를 서로 바꾼 것으로 데이터의 크기가 너무 커 변환과정에서 너무 오랜 시간이 필요할 때, 로딩을 먼저하고 변환을 그 후에 진행하는 것이다.
- ETL은 데이터웨어하우스(저장구조)를 마련하는 데에 매우 중요하다.
- ELT 오픈소스도구로는 Apache NIFI, KNIME, Talend, Pentaho, Stream Sets등이 있다.
3. Data Warehouse(DW) VS Data Lake
- DW는 일종의 데이터 저장소인데, raw데이터가 아닌 사용자 의사결정에 도움을 줄 수 있도록, 여러 시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리한다.
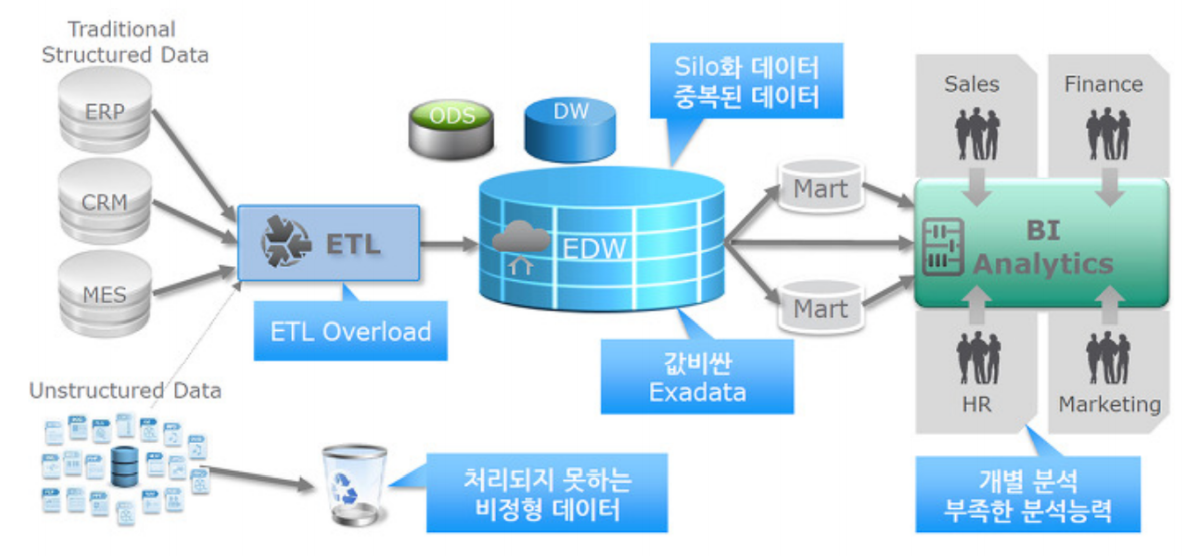
- 위의 아키텍처에서 ETL를 통해 데이터가 Enterprise Data Warehouse(EDW)에 적재되고, 이 데이터들은 mart라고하는 주제별 테이블로 처리되어, 사용자에 따라 적절한 도구(ex. BI)를 통해 분석된다.
- DW는 다음과 같은 단점을 가지는데, 먼저 ELT를 통해 대량의 데이터를 주기적으로 가져오고 복잡한 절차로 통합하기때문에 상당한 부하가 가중되고, 유지비용도 크다. 한편, 테이블이 잘 관리되지 않을 경우 중복데이터가 생기고 데이터 사일로(data silo)현상을 야기할 수있다. 가장 큰 한계로는 정형된 데이터만 취급하고 비정형데이터는 처리하지 못한다.
- Data Lake는 DW의 한계를 보완하고자 나타난 개념이다.
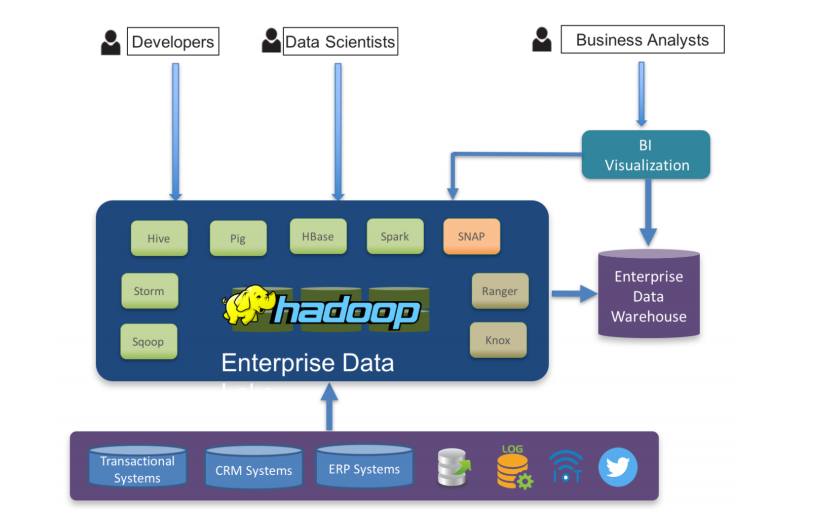
- DW가 정형데이터만 취급하는 것에 반해, Data Lake는 정형, 비정형, 반정형에 상관없이 원래 형식 그대로 저장하여 분석에 활용한다. 때문에 DW에 비해 더 큰 데이터 저장공간이 필요하다.
- Data Lake에는 다양한 빅데이터 기술 (ex.hadoop, Spark 등)이 포함되며, DW와 Data Lake를 함께 하이브리드의 형태로 사용하기 한다.
4. 데이터 스트림(Data Stream) VS 배치(Batch)
- 먼저, 데이터 적재 유형을 bounded data와 unbounded data로 나누어 설명할 수 있는데,
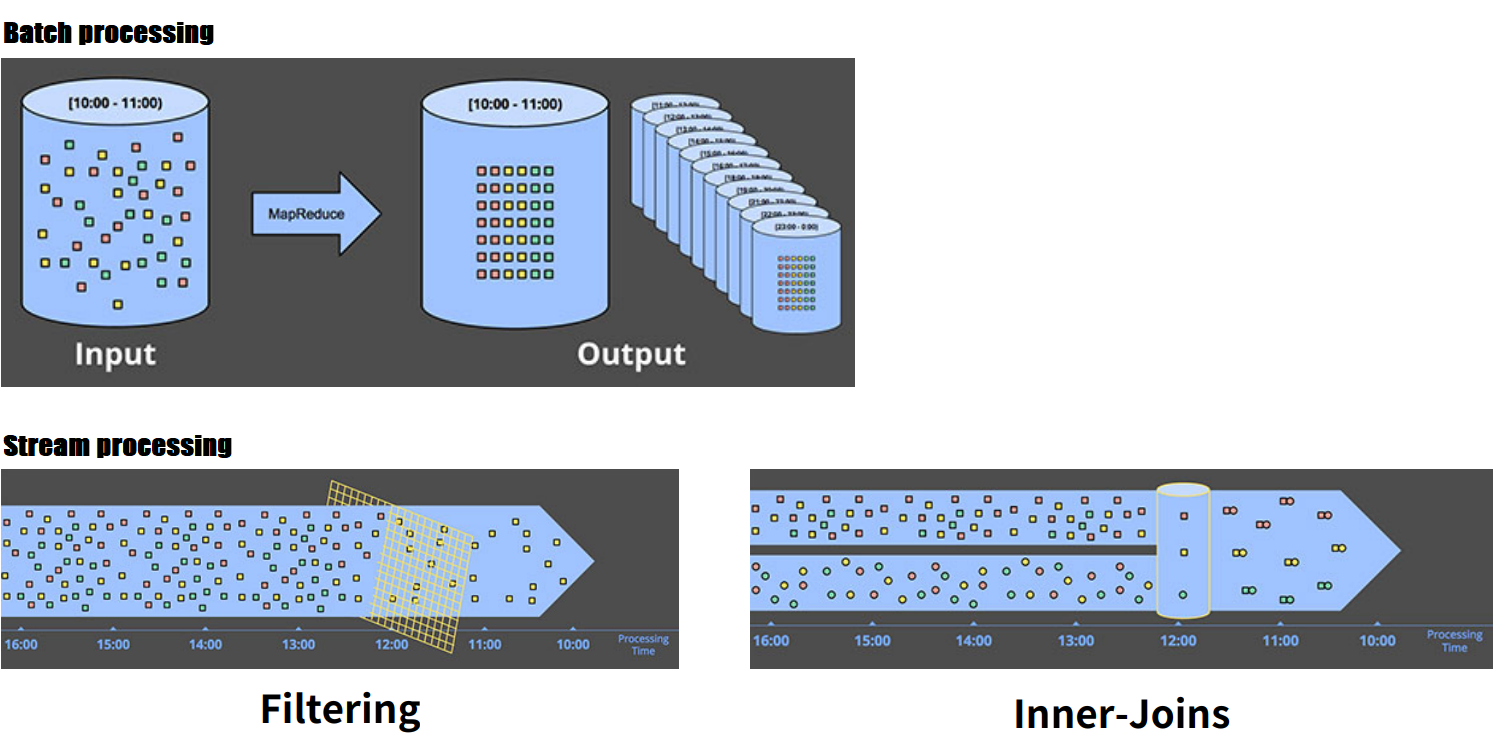
- bounded data는 일단 저장되면 이후 변화가 없는 데이터이다. 이러한 데이터들은 묶어서 특정 시간에 한 번에 일괄처리하는데 이러한 처리방법을 배치처리(Batch processing)한다. 이에 대한 예시로는 매 월 단위 매출 데이터, 매 월 신규 고객 유치 수 등이 있는데, 이 경우에는 월 마다 데이터를 한꺼번에 처리할 수있다.
- 한편, unbounded data는 끊임없이 지속적으로 적재되는 데이터로 임의의 주기를 정해 배치처리하거나 혹은 스트림 처리(Stream processing)할 수 있다. 예컨대 시스템 로그 데이터, 주식 가격 변동 데이터 등은 시간 혹은 일별 단위로 배치 처리 하거나, 필터링 등의 세부 프로세스를 거쳐 필요한 정보만 실시간으로 스트림 처리할 수 있다.
-
한편, Micro Batch란 배치의 주기를 상대적으로 짧게 설정하여 준 실시간 처리의 효과를 내는 방법으로 일종의 스트림 처리로 분류된다.
-
아래는 스트림 처리 인프라 아키텍처의 한 예시이다. 앞 부분에는 서버 혹은 앱에서 지속적으로 생성되는 로그 데이터를 데이터 스트리밍 오픈 소스인 Apache Kafka를 통해 실시간으로 불러와 Spark streaming으로 전송하는 과정이 표현되어 있다. 여기서 Kafka는 데이터 유실을 방지하기 위해 초반에 데이터를 잠시 담아두는 저장고(queue) 역할을 한다. Kafka에서 넘어온 데이터는 Spark streaming에서 실시간으로 분석되며, 그 분석 결과는 HBASE라고 하는 일종의 NoSQL데이터 베이스에 저장된다.
5. 워크플로우(Workflow)
-
사전적으로는 작업 절차를 통한 정보 또는 업무의 이동로 정의되며, 데이터 워크플로우는 데이터 처리의 작업 절차를 의미한다.
-
예컨대 ETL도 워크플로우 스케쥴링 도구를 통해 자동으로 진행할 수 있다.
-
아래는 워크플로우의 예시로 노드와 노드 간의 화살표를 통해 작업, 데이터의 흐름을 쉽게 확인할 수 있다.
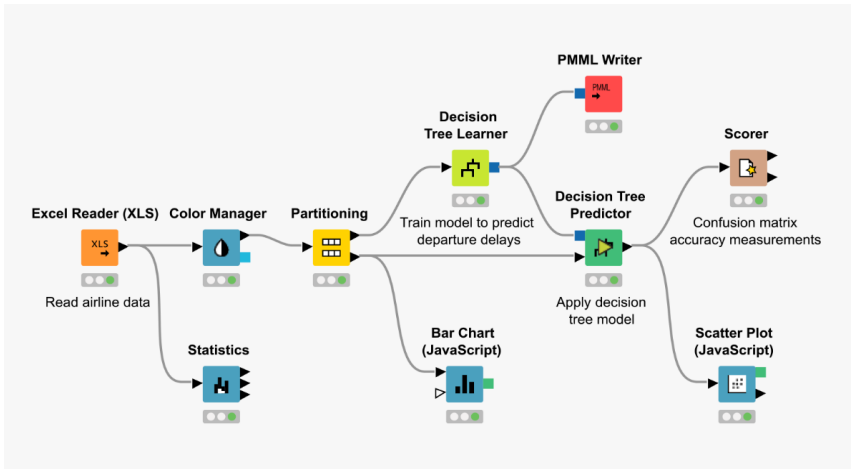
출처: www.knime.com -
워크플로우는 Directed Acyclic Graph(DAG)의 속성을 가지거나 그렇지 않을 수 있는데, DAG는 방향성 비순환 그래프로 해석하며 이를 준수해야한다는 것은 워크플로우가 방향을 가지되 서로 순환하는 형태가 없어야 함을 의미한다.
-
워크플로우 엔진으로는 Apache Oozie(html기반), Apache Airflow(Python기반) 등이 있다.
6. 컴퓨터 클러스터(Computer Cluster)
-
여러 대의 컴퓨터들이 네트워크 상으로 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 의미한다.
-
물리적으로는 여러 컴퓨터이지만 외부 사용자는 마치 한대의 컴퓨터 인 것으로 인식하며 사용할 수 있다.
-
컴퓨터 클러스터의 구성요소는 다음과 같다.
- Node(Master + Slave): 서버
- Network: 네트워크
- OS: 운영체제
- Middleware: 이 클러스터를 동작하게 하는 미들웨어
-
서버의 확장을 통해 우수한 성능을 내기위한 목적을 가진다. 컴퓨터 클러스터를 구축하기위해서는 분산 컴퓨팅(distributed computing) 기술이 필요하다.
- 이러한 방법은 Scale out 형태의 서버 구성에 속한다. 네트워크 상의 서버의 수를 늘려 컴퓨팅 성능을 향상시킴으로써, 기존 1대의 컴퓨터(서버)가 하던 일을 N개의 컴퓨터가 나눠서 처리하도록 하는 것이다. cf) 이와 대조되는 개념은 Scale up으로, 이는 컴퓨터의 하드웨어인 RAM, CPU, Disk 등 그 구성요소 자체를 교체 혹은 추가로 설치하여 컴퓨팅 성능을 향상시키는 것이다. 따라서 기존의 1대의 컴퓨터(서버)가 5의 능력을 가질 수있도록 기능을 개선시키는 것으로 이해할 수 있다.
-
클러스터에서는 단일장애지점인 SPOF(Single Point Of Failure)가 없어야 하며, 고가용성인 HA(High Availability)가 유지되어야 한다. 다시말해, 시스템 구성 중에 동작하지 않으면 전체 시스템이 중단되는 요소가 없어야 하고, 서버와 네트워크, 프로그램 등의 시스템이 지속적으로 운영가능해야한다.
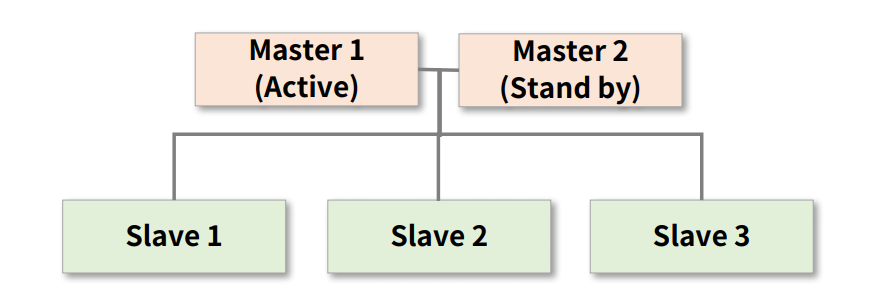
출처: 패스트 캠퍼스 예를 들어, 위 그림에서 Master 1이 피치 못하게 중단 될 경우, 대비책인 Master 2가 동작하게 한다.
7. SQL
-
SQL은 구조적 질의 언어 즉, Structured Query Language의 약자로 관계형 데이터베이스의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
-
데이터베이스에서 정형 데이터(structured data)분석을 위한 필수 요소이다.
-
내부적으로는 DDL, DML, DCL, TCL로 구성된다.
(1) DDL: Data Definition Language
- 데이터 정의 언어로 관계형 데이터베이스에 테이블 구조를 정의하고 생성(CREATE)하거나 기존 테이블의 구조를 변경(ALTER) 또는 삭제(DROP)하는 명령어이다.
(2) DML: Data Manipulation Language
- 데이터 조작 언어로 테이블에 들어있는 데이터들을 조회(SELECT, GROUP BY, HAVING)하거나 변경(INSERT, DELETE, UPGRADE, JOIN)하는 명령어이다.
(3) DCL: Data Control Language
- 데이터 제어 언어로 테이블에 대한 사용 권한 부여(GRANT) 및 사용 회수(REVOKE)를 지정하는 명령어이다. 사용자가 테이블을 조회하거나 변경할 수 없다면, 데이터베이스 관리자에게 허가를 요청해야한다.
(4) TCL: Transaction Control Language
- 트랜잭션 제어 언어로 트랜잭션 작업 결과를 반영(COMMIT)하거나 이를 취소, 조작 명령 전으로 복구(ROLLBACK)하는 데에 쓰이는 명령어이다.
- 한 사용자가 테이블에 어떤 데이터를 입력 중 혹은 수정 중 일 때, 다른 사용자들이 이 데이터를 조회하는데에 문제가 생길 수 있다. 이를 해소하기위해 데이터베이스는 트랜젝션이라는 단위로 관리되어진다. 예를 들면, COMMIT전 까지 다른 사용자에게 수행 결과가 보여지지 않는 등의 조치를 취할 수 있다. cf) 이에 반해 NoSQL은 트랜잭션이 명확하지 않다는 특징을 갖는다.
-
데이터 분석에 있어서는 DDL과 DML이 가장 중요하다
-
SQL 문법은 데이터베이스에 따라 상이 할 수 있다.
8. Hadoop
-
하둡은 Open Source Java Software Framework 즉, 특정 기능을 동작하게 하는 소프트웨어 뼈대를 제공한다.
-
하둡은 저장기능을 맡는 하둡 분산 파일 시스템(HDFS: Hadoop Distributed File System)과 연산기능을 맡는 맵리듀스(MapReduce)로 구성되어있다.
-
HDFS는 하둡의 분산형 파일 시스템으로 여러 대의 서버에 데이터를 나누어서 저장하는 기능을 한다.
- 데이터의 위치, 상태 등 meta정보를 관리하는 Name node와 실제 데이터를 저장하고 보내는 역할을 하는 Data node들로 이루어져있다.
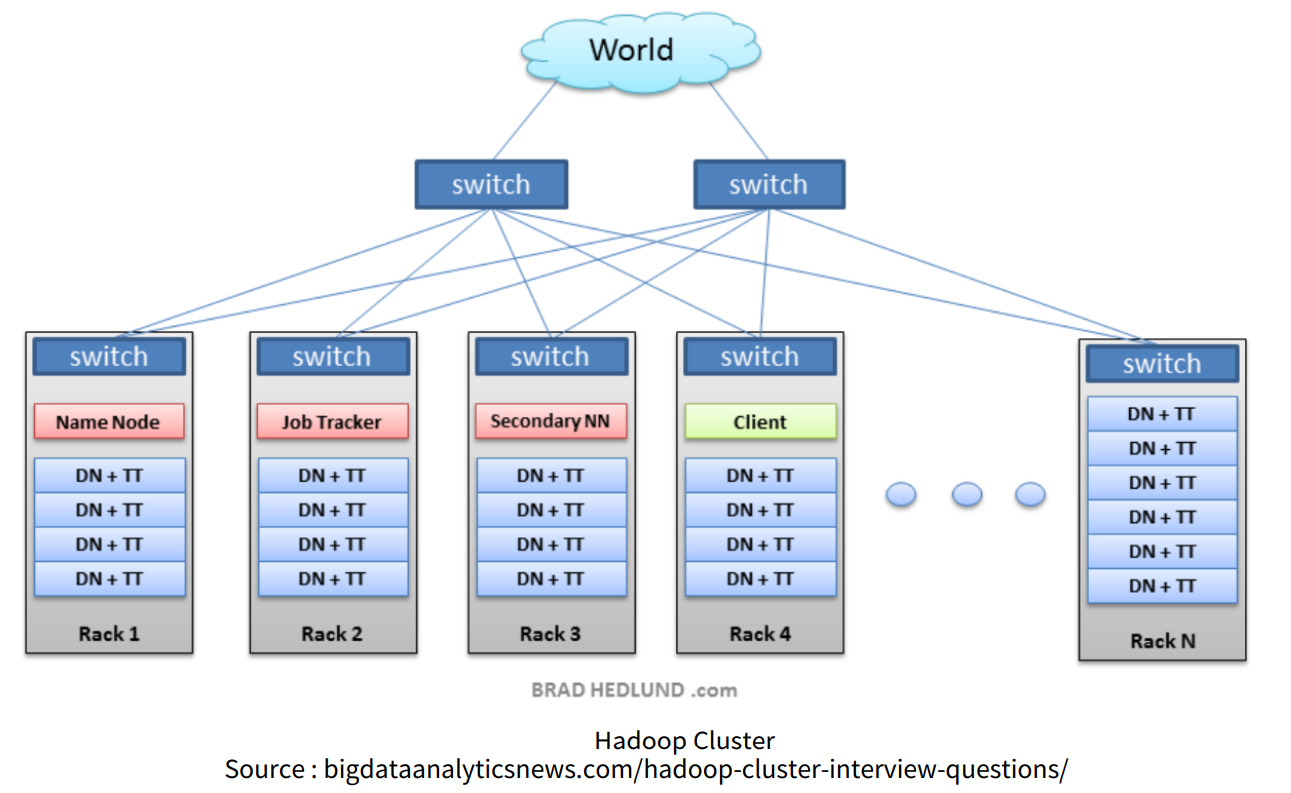
출처: 패스트캠퍼스 클라이언트가 어떤 데이터를 HDSF에 저장하고자 할 때, 시스템적으로 먼저 네임 노드에 어디에 저장해야 할지를 묻게되어있다. 관리자 역할을 하는 네임 노드는 클라이언트에게 몇 번째 데이터 노드에 저장해야하는 지를 알려주고, 이를 확인받은 클라이언트는 해당 데이터 노드에 데이터를 전송할 수 있다. 이후에는 데이터 자가복제인 단계를 거치는데 이는 데이터 유실을 방지하기 위한 HDSF의 기능이다.
하둡 클러스터는 실제로는 여러대의 서버로 구성되지만, 실사용자는 이를 한 개의 서버로 인식하며, 일부 서버에 장애가 생기더라도 전체 시스템에는 영향을 주지 않도록 설계되어있다.
-
MapReduce는 map과 reduce라는 두 개의 함수를 조합하여 데이터를 처리하는 프레임 워크를 이미한다. 여기서 map는 특정 단위로 나누어진 데이터를 계산하는 것이고, reduce는 앞서 나눠진 단위들을 다시 동일한 key를 바탕으로 합쳐 연산하는 것이다. 아래의 그림은 텍스트 데이터에서 단어를 카운트하는 맵리듀스 과정을 나타낸 것이다.
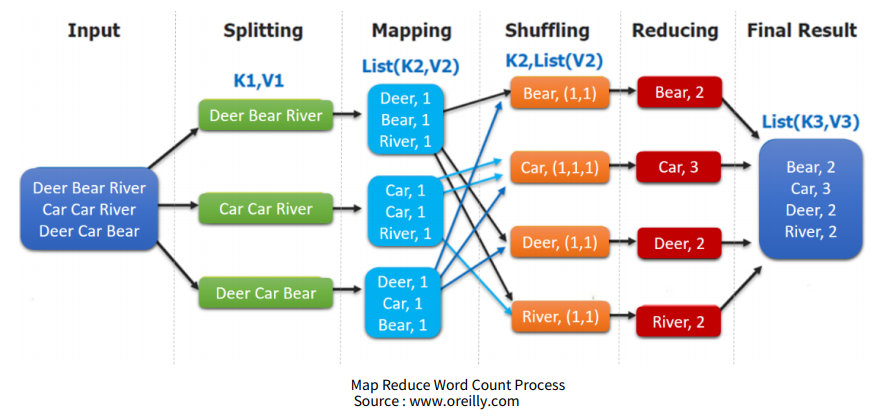
출처: 패스트캠퍼스 - 최근에는 맵리듀스는 잘 활용되지 않고 스파크를 더 많이 활용한다고 한다. 그렇지만 맵리듀스의 기본 매커니즘은 많은 오픈소스에서 유지되고 있고, 분산 컴퓨팅의 기본이기 때문에 알아두어야 할 필요가 있다.
9. Spark
- 분산환경에서 동작하는 In-memory 기반의 데이터 처리용 오픈소스이다.
- 메모리를 활용을 극대화하여 하둡의 맵리듀스와 유사한 역할을 하면서도 연산속도가 월등히 빠르다.
- Scala, Python으로 개발 가능하다.
- 최근에는 메모리 가격이 저렴해지고 하드웨어 성능도 많이 개선되어 맵리듀스보다는 스파크를 선호하는 추세이다.
- RDD: Resilient Distributed Datasets
- 스파크에서 활용되는 내부 데이터 모델
- 병렬처리가 가능하고 장애 발생시 스스로 복구될 수있는 내성을 가진다.
- RDD는 최초 생성된 후 바뀌지 않으며 다른 형태로 변환이 필요 할 경우는 새로운 RDD를 만들어 내는데, 이러한 특징은 장애 발생 시 복구에 유리하다. 다시말해, RDD가 진행된 절차를 모두 기억하고 있다가 그대로 수행함으로써 빠르게 복구가 가능한 것이다.
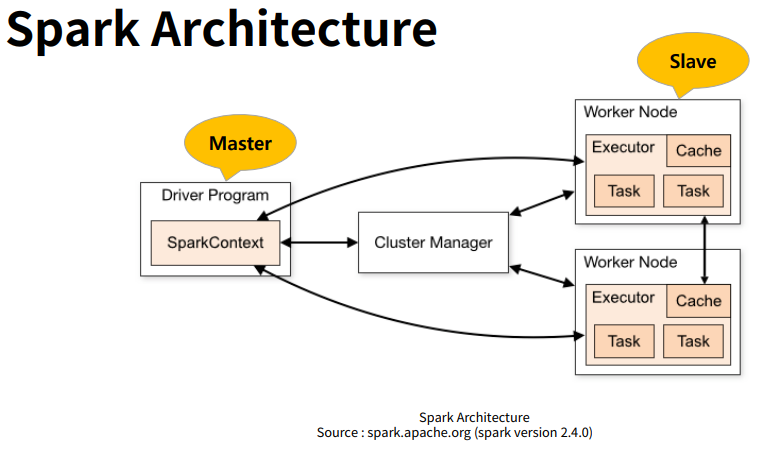
출처: 패스트캠퍼스 - 위의 그림에서 볼 수 있듯이 스파크는 분산 컴퓨팅 환경에서 특정 작업에 대한 Master node역할을 하는 Driver Program과 실제 연산을 담당하는 Slave node 역할의 worker node들로 구성되어 있다.
- 분산 컴퓨팅 기능 뿐만아니라 다음과 같은 기타 기능을 포함한다.
- Spark SQL: SQL을 통한 데이터 처리
- Spark Streaming: 실시간 스트리밍 데이터를 처리
- Spark Mllib: 머신러닝 알고리즘 라이브러리
- Spark GraphX: 그래프 연산용 모듈
- 하둡과 스파크 비교
- 하둡은 디스크 저장기반으로, 맵리듀스가 중간결과를 HDFS에 기록하기 때문에 read와 write 속도가 느리다. 한편, 스파크는 디스카가 아닌 메모리에 저장하기 때문에 데이터 처리 속도가 하둡의 10~100배로 빠르다.
- 하둡은 대용량 배치처리에 강점이 있고, 스파크는 준 실시간처리에 많이 활용된다.
- 한편, 하둡은 Java로 스파크는 Scala로 쓰여진다.
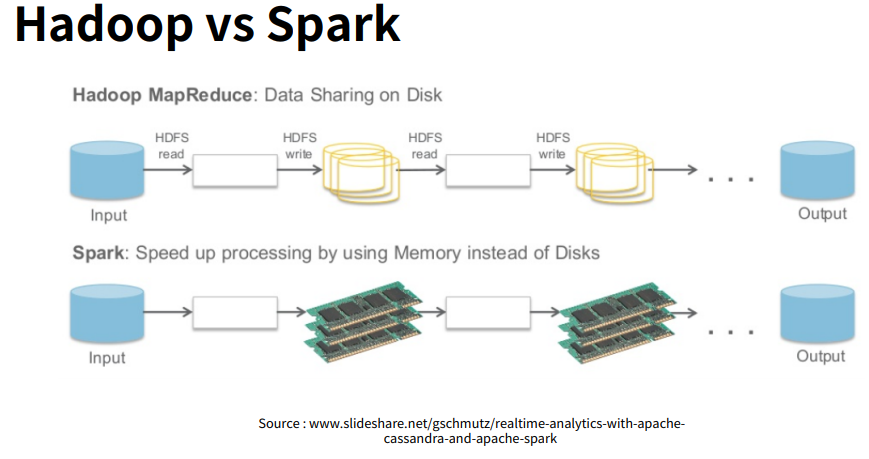
출처: 패스트캠퍼스
10. Hive
- 하둡 기반의 데이터 웨어하우스 소프트웨어로서 HDFS, Hbase 등 여러 하둡 에코들과 호환이 가능다.
- SQL기반의 데이터 요약, 질의 및 분석 기능을 제공한다.
- 기본 분석을 위한 QL(SQL-Like)언어와 다수의 내부 함수를 제공한다. 또한, UDF(User defined function)도 지원한다.
-
가장 큰 장점은 다양한 파일 형식으로 전환이 가능 하다는 것이다. 예컨대 JSON이나 xml파일도 별도의 변환 과정없이 하이브에서 바로 읽고 질의할 수있다.
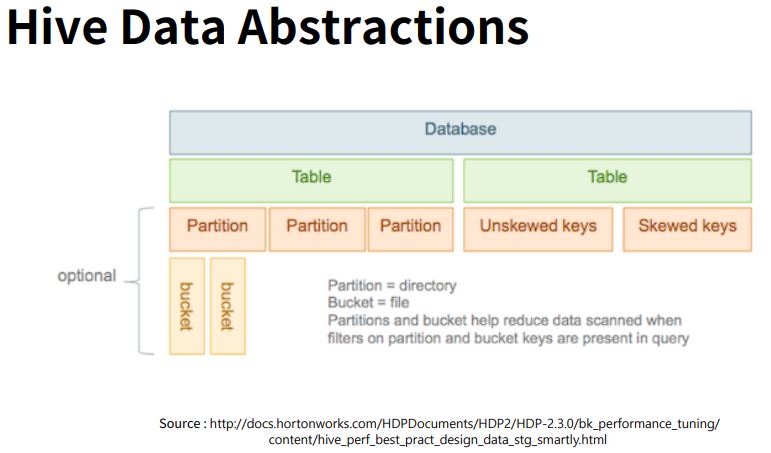
출처: 패스트캠퍼스 - 하이브는 HDFS와 연동되며 데이터베이스부터 테이블과 파티션까지는 실제 HDFS의 물리적인 디렉토리로 구조화(ex. /user/hive/warehouse/table/partition)된다. 한편, 버킷은 별도의 폴더 없이 파일 단위로 저장된다.
-
결국 하이브는 SQL을 통해 HDFS의 데이터를 처리 혹은 조회하는 기능을 하는데, 이는 맵리듀스의 java 코드를 직접 입력하는 것보다 훨씬 간단하고 효율적이다(아래 아키텍쳐에서 코드 비교). 다시말해, SQL로 질의하면 내부적으로는 맵리듀스나 기타 언어로 전환하여 수행되는 구조로, 빠른 결과를 가져다줄 뿐만아니라 프로그래밍에 있어 사용자 오류가 적다.
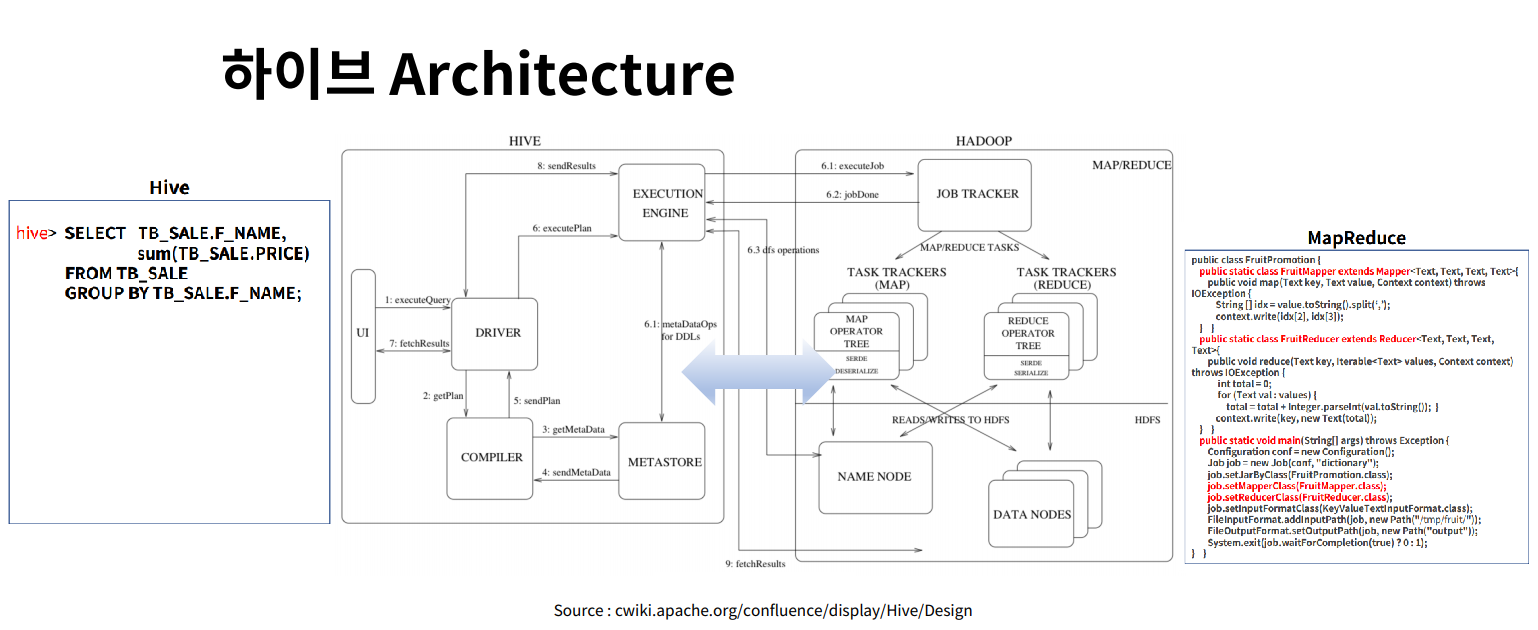
출처: 패스트캠퍼스 - 하이브처럼 HDFS에 저장된 데이터에 대한 SQL처리를 제공하는 오픈소스들을 총칭해 SQL-on-hadoop혹은 Hadoop SQL이라고 하며, Apache Impala, presto, Apache DRILL 등이 있다. 각각은 내부 엔진에 따라 그 성능 및 기능이 다르며, 빅 데이터 인프라를 갖춘 조직이라면 어떠한 경우이든지 간에 이 중 하나를 갖추고 있을 가능성이 크다.
11. NoSQL
- NoSQL 데이터 베이스는 빅 데이터 시대에 접어들며 기존의 관계형 데이터 베이스 이용 시, 대량의 데이터 적재에 따른 비용이 크게 증가하고 처리 성능에 있어 한계에 도달했기 때문에 등장하였다.
- NoSQL은 Not only SQL의 줄임말이며, 기존 관계형 데이터 베이스의 고정형 테이블 도식이 불필요하다. 적재와 조회에 성능을 최적화했기 때문에, 오히려 테이블 간 관계 설정 및 join이 지양된다. (예컨대, 대량의 시스템 로그 적재에는 테이블 간 join이 필요치 않기 때문에 NoSQL를 활용하는 것이 바람직하다.)
-
NoSQL 데이터 베이스의 종류에는 Apache HBASE, mongoDB, cassandra, elasticsearch 등이 있다. 다음은 NoSQL의 대표 데이터베이스 중 하나인 HBASE의 아키텍쳐이다. Scale out을 통한 수평적 규모 확장이 가능함을 알 수 있다.
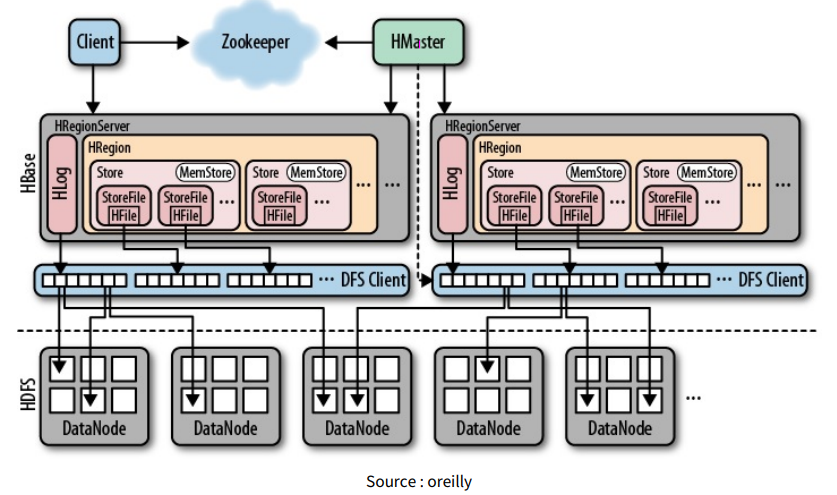
-
CAP이론
-
CAP는 각각 Consistency(일관성), Availabilty(가용성), Partition Tolerance(분할성)을 의미한다.
일관성: 모든 사용자가 같은 순간에 같은 데이터를 볼 수 있다.
가용성: 모든 클라이언트는 항상 읽기, 쓰기가 가능하다.
분할성: 시스템이 물리적 네트워크로 분할된 상태에서 정상 동작한다.
-
분산시스템에서 이 세 가지 속성을 모두 만족할 수 없다는 것이 이 이론의 핵심이다. 다시말해, 현존하는 분산시스템은 아래와 같이 최대 두 가지 속성까지만 만족할 수있다.
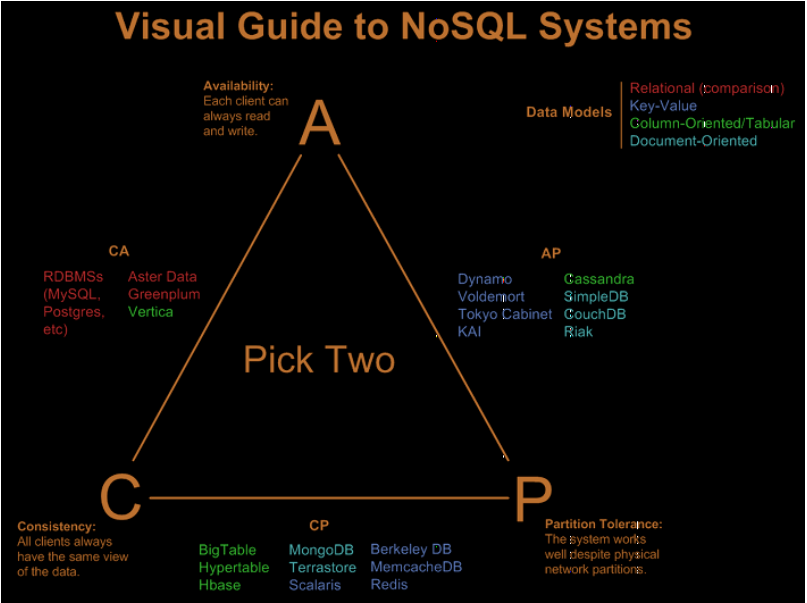
출처: 패스트캠퍼스 -
-
관계형 데이터베이스(RDB)와의 비교
-
관계형 데이터는 트랜잭션이 안전하게 수행되는 것을 보장하기위해 다음과 같은 ACID 특성을 갖는다.
Atomicity(원자성): 한 트랜잭션 안의 모든 작업은 모두 성공하거나 모두 실패한다.
Consistency(일관성): 한 트랜잭션이 성공하면 모든 데이터는 동시에 일관된 상태로 유지된다.
Isolation(고립성): 한 트랜잭션이 수행되는 동안 다른 트랜잭션이 수행될 수 없다.
Durability(지속성): 트랜잭션이 성공하면 해당 최종 상태는 영원히 반영된다.
-
한편, NoSQL 데이터 베이스는 BASE라는 특성을 갖는다.
Basically Available: 데이터는 어떠한 경우에든 항상 활용될 수 있다. (Isloation과 대립되는 특성)
Soft-State: 분산 노드 간 업데이터는 데이터가 노드에 도달한 시점에 갱신된다.
Eventual Consistency: 지연된 일관성으로 해석하며, 모든 노드에서 동시에 보장되는 것이 아니라 시간이 지나면 결국에 모든 노드에서 일관성이 보장되는 것이다.
-
- 모든 조직이 NoSQL 데이터 베이스로 무리하게 전환할 필요는 없다. 하지만 용도가 명확할 경우 즉, 실시간 대용량 데이터를 적재하는 것이 필요하고, 테이블 간 join 등의 처리라 거의 없는 경우 그리고 추후 데이터 베이스 확장이 유연해야하는 경우에는 NoSQL을 활용하는 것이 바람직할 것이다.
Reference
- 패스트 캠퍼스 데이터 분석 입문 올인원 패키지 강의